What is Machine Learning?


Machine Learning is a programming technique that teaches computers to recognize patterns and make decisions without providing an explicit set of rules to perform these tasks. It is a special kind of computer program, where instead of programming a procedure that executes a step by step instruction, the program learns through a set of examples of the problem to solve. More examples, better the learning. A collection of examples of the problem is referred to as the input data.
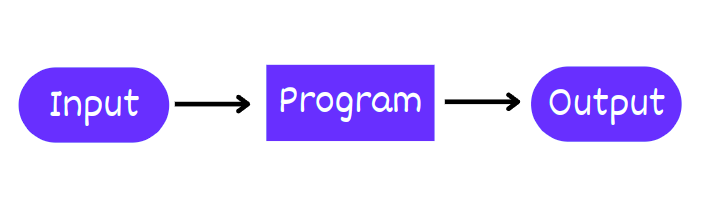
Regular programs are made up of procedures, a set of instructions to complete a task. This works well where the number of possible steps are limited to achieve the outcome. A simple example would be a computer program that can be used to calculate the square of a number.
(define (square x) (* x x))In this case the program takes a numerical input and manipulates it to calculate and return the square of that as the output. So simply put a program takes an input and produces an output. This is accomplished through a set of instructions abstracted as procedures. Procedural Abstraction or Black Box abstraction is a major tool to handle complexity when building computer programs. The way to do it is to draw a box around a specific chunk of functionality and give it a name, using this technique one can design complex ideas without having to worry about the implementation of each box.
The acts of the mind, wherein it exerts its power over simple ideas, are chiefly these three:
- Combining several simple ideas into one compound one, and thus all complex ideas are made.
- The second is bringing two ideas, whether simple or complex, together, and seeing them by one another so as to take a view of them at once, without uniting them into one, by which it gets all its ideas of relations.
- The third is separating them from all other ideas that accompany them in their real existence: this is called abstraction, and thus all its general ideas are made.
—John Locke, An Essay Concerning Human Understanding (1690)
So building software is essentially the ability to break down your requirement into a bunch of boxes and knowing the set of instructions to implement each box. This is how almost all software is built and works pretty well.
However the same approach does not work for all real world problems. For example we can recognize a dog or a cat without even thinking but the same is very difficult for computers. The reason it is difficult for computer to do that is because it is hard to translate all the set of instruction required to make that determination. This exact problem was recognized by Arthur Samuel while he was working at IBM. As per him instead of telling the computer the exact steps required to solve a problem, show it examples of the problem to solve, and let it figure out how to solve it itself. This formed the foundation of what we call today as Machine Learning.

Arthur Samuel defined Machine Learning as follows:
Machine learning is a computational method for achieving artificial intelligence by enabling a machine to solve problems without being problem-specific programming (Samuel, 1959).
Arthur's profound intuition turned out to be extremely effective, his checkers program learnt so much that it beat the self-proclaimed checkers master Robert Nealey in a game in 1962. This was an extraordinary feat for the time and made the public realize the capabilities of computers.

To this end he proposed the following
Suppose we arrange for some automatic means of testing the effectiveness of any current weight assignment in terms of actual performance and provide a mechanism for altering the weight assignment so as to maximize the performance. We need not go into the details of such a procedure to see that it could be made entirely automatic and to see that a machine so programmed would "learn" from its experience.
There is a lot to unpack here. Let us try to understand this with a simple example. Let us say if we had an online store and had to predict the sales of the store based on advertising spend. To do this you need to find a function that can represent this relationship mathematically. For simplicity we will assume they have a liner relationship. That would imply the relationship will look something like this
Y=B0+B1X
In the above equation B0 and B1 are the coefficients which are referred to as weights in Samuel's proposal. Y is the value that we want to compute which in this case is the sales. X in the independent variable and that in our case is the advertising spend.
The performance of our function can be measured by checking how far off the predicted value Y is from the expected value in our input data. Now that we understand these terms the objective is to try a bunch of weights (function coefficients) in a way that we can find the best combination of these weights that give the closest sales prediction to our examples.
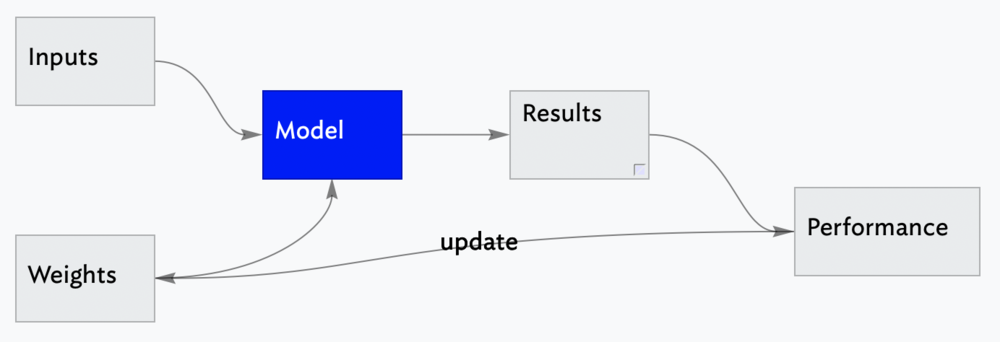
To summarize, a machine learning model is trained by providing inputs (previous examples of the problem) and weights. By varying the weights we can tweak the performance and the goal is to tweak is in a way that improves its performance. This idea is the foundation of supervised Machine Learning techniques especially Neural Nets.
One important thing to note is that when we train a ML model we hold a subset of the training data to be used as evaluation data, which tests how accurate the machine learning model is when it is shown new data. This data is called the validation data and is used to give an unbiased estimation of model's performance during the development stage of the model.
Once a model is trained then a model can take an input and give an output. This is referred as Machine Learning Inference. At this point it behaves quite similar to any regular program.
Next let us look into the four types of machine learning algorithms that are used by practitioners.
Supervised learning
Supervised learning builds on the idea proposed by Arthur Samuel's, in this case the machine is trained by examples. The machine is provided with a well labeled training data, the algorithm identifies the patterns in data, learns from observations and makes prediction. Labeled data means that it has both input and the expected output and hence can be used for machine teaching. The algorithm makes predictions and is improved by adjusting the weights until the algorithm reaches a high level of performance. Here is an example of supervised learning.
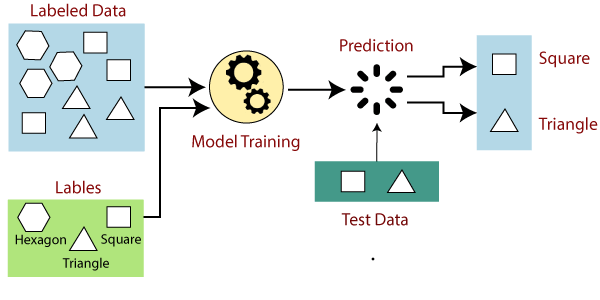
Supervised learning itself can be further divided into two categories.
-
- Classification: In classification tasks, the machine learning program must draw a conclusion from observed values and determine to what category new observations belong. For example, when filtering emails as ‘spam’ or ‘not spam’, the program must look at existing observational data and filter the emails accordingly.
- Random Forest
- Decision Trees
- Logistic Regression
- Support vector Machines
-
Regression: In regression tasks, the machine learning program must estimate – and understand – the relationships among variables. Regression analysis focuses on one dependent variable and a series of other changing variables – making it particularly useful for prediction and forecasting. Some of the popular
- Linear Regression
- Regression Trees
- Non-Linear Regression
- Bayesian Linear Regression
- Polynomial Regression
Unsupervised learning
Unsupervised learning is a machine learning technique that studies data to identify patterns. It does not require a labeled dataset or an operator. Instead, the machine determines the patterns and relationships by studying the available data. Its ability to discover the similarities and differences in data make it an idea tool for data exploration, segmentation and image recognition.
Some common unsupervised learning approaches include:
- Clustering: Clustering involves grouping sets of similar data (based on defined criteria). It’s useful for segmenting data into several groups and performing analysis on each data set to find patterns.
- Dimension reduction: Dimension reduction reduces the number of variables being considered to find the exact information required.
Some popular Unsupervised learning algorithms
- K-means clustering
- KNN (k-nearest neighbors)
- Hierarchal clustering
- Anomaly detection
- Principle Component Analysis
- Independent Component Analysis
- Apriori algorithm
- Singular value decomposition
Semi-supervised learning
Semi-supervised learning is an approach that falls in between supervised and unsupervised learning. This technique uses both labelled and unlabelled data. A small amount of labeled data when used together with large amount of unlabeled data can lead to drastic improvement in learning accuracy. This happens because the labeled data has meaningful tags that the algorithm can understand the data, whilst unlabelled data lacks that information. This is mostly useful when the size of data is huge and the cost of labeling the entire dataset would be very large.
Reinforcement learning
Reinforcement learning is a machine learning technique in which an agent learns in an interactive environment through a process of trial and error. The agent is rewarded for desired actions and penalised for undesired actions. In this approach the agent learns by exploring the environment and improves the performance by getting maximum positive rewards.
Machine Learning has come a far way from just being an academic topic to being part of all walks of life, the possibilities are constantly expanding. At Newron we are excited about the possibilities ML offers and are building tools to help machine learning practitioner build better models through faster experimentation and iteration.